Training Data from words
முதலில் இரண்டு வாக்கியங்களை மட்டும் எடுத்துக் கொண்டு, அதற்கான ட்ரெய்னிங் டேட்டா உருவாக்குவது பற்றிக் காண்போம்.

இங்கு ‘சூரியன்’ எனக்கொடுத்தால், வரவிருக்கும் அடுத்த வார்த்தை ‘உதிக்கும்’; இவ்விரண்டும் சேர்ந்தால் வரவிருக்கும் அடுத்த வார்த்தை திசை. இதே முறையில், எந்தெந்த வார்த்தைகளைத் தொடர்ந்து, என்னென்ன வார்த்தைகள் வரலாம் எனும் பயிற்சிக்குத் தேவையான டேட்டா, ஒரு வாக்கியத்தில் உள்ள அனைத்து வார்த்தைகளையும் மடக்கி மடக்கி தயாரிக்கப்படுகிறது. இதே போல கோடிக்கணக்கான வாக்கியங்களுக்குச் செய்யும்போது, சூரியனைத் தொடர்ந்து வரவிருக்கும் அனைத்து possible வார்த்தைகளும் ஒரு கட்டத்தில் ட்ரெய்னிங் டேட்டாவாகிவிடும்.
அடுத்ததாக, நடைபெற வேண்டியது டோக்கனைசேஷன். இந்த ட்ரெய்னிங் டேட்டாவை அப்படியே நியூரல் நெட்வொர்க்குக்குள் அனுப்பாமல், டோக்கன் போட்டு அனுப்ப வேண்டும். உதாரணத்துக்கு self-service ஹோட்டல்களில் உணவினை ஆர்டர் செய்யும் பொழுது, அதை ஒரு பேப்பரில் எழுதிக் கொண்டு ஒரு டோக்கன் அளிப்பார்கள். பின்னர் அந்த உணவு ரெடியானதும், அவர்கள் கொடுத்த டோக்கனை வாங்கிக் கொண்டு உணவுப் பொருளை அளிப்பார்கள். அதாவது நாம் டோக்கன் போட்டு உள்ளே அனுப்பிய உணவுப் பொருள், அதன் ப்ராசஸ் முடிந்து வெளியே வரும்போது அந்த டோக்கனிலிருந்து விடுவிக்கப்பட்டு நம் கைக்கு கிடைக்குமல்லவா! இதே முறை தான் நியூரல் நெட்வொர்க்கிலும் பயன்படுத்தப்படுகிறது. ஒவ்வொரு வார்த்தைகளும் தனித்தனியாக டோக்கனை பெற்றுக் கொண்டு நெட்வொர்க்குக்குள் செல்கிறது. பின்னர் ப்ராசஸ் முடிந்து வெளிவரும்போது, தனக்கான டோக்கனிலிருந்து விடுவிக்கப்பட்டு வார்த்தைகளாக வெளி வருகிறது.
ஆகவே, மேலே உருவாக்கிய ட்ரெய்னிங் டேட்டாவில் உள்ள வார்த்தைகளுக்கு டோக்கன் அளித்து பின்வருமாறு மாற்றுவோம்.

கணிதத்தைப் பொறுத்தவரை, ஒரு அடைப்புக்குறிக்குள், இதுபோல தொடர்ச்சியான எண்களைக் கொண்ட அமைப்பு முறைக்கு வெக்டார் என்று பெயர். பல்வேறு வெக்டார்களைக் கொண்டது டென்சார் ஆகும். நமது ட்ரெயினிங் டேட்டா என்பது இப்போது ஒரு டென்சாராக மாற்றப்பட்டுவிட்டது. இவற்றை வைத்து டென்சார்flow கணக்கீடுகள் நடைபெற வேண்டுமெனில், அதில் உள்ள அனைத்து வெக்டார்களும் ஒரே டைமென்ஷனில் இருக்க வேண்டியது அவசியம். ஆகவே, இருப்பதிலேயே பெரிய வெக்டரின் அளவில் மற்ற அனைத்தும் மாற்றப்பட்டு, காலியிடங்களில் ஜீரோ நிரப்பப்படுகிறது.

பின்னர் அவுட்புட் வெக்டரானது மல்டி கிளாஸ் கிளாசிஃபிகேஷன் செய்யப்படுவதற்கு ஏதுவாக, ப்ரெடிக்ட் செய்யப்பட வேண்டிய அனைத்து வார்த்தைகளும் சேர்ந்து ஒரு வெக்டராகி, ஒவ்வொன்றும் one-hot encoding முறையில் குறிக்கப்படுகிறது.
கடைசியாக, ஒவ்வொரு வெக்டரில் உள்ள வார்த்தைகளும் இன்புட் லேயர் வழியே உட்சென்று, தனக்கான அவுட்புட் வார்த்தையுடன் இணைவதற்கு ஏற்றார் போல வெயிட்ஸ் மற்றும் பயாசை திருத்தம் செய்து கொள்கிறது. இன்புட் லேயரில் உள்ள நியூரான்களின் எண்ணிக்கை, இருப்பதிலேயே பெரிய வாக்கியத்தில் உள்ள வார்த்தைகளின் எண்ணிக்கைக்கு ஏற்ப அமையும். அவுட்புட் லேயரில் உள்ள நியூரான்களின் எண்ணிக்கை, ப்ரெடிக்ட் செய்யப்பட வேண்டிய மொத்த வார்த்தைகளின் எண்ணிக்கைக்கு ஏற்ப அமையும்.
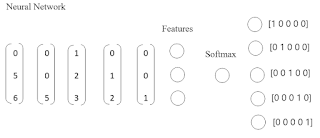
இங்கு நியூரல் நெட்வொர்க்குக்குள் நுழையும் எண்கள், வார்த்தைகளைக் குறிப்பதால் அவற்றை சரியான வரிசைமுறையில் செலுத்த வேண்டியது அவசியம். எனவேதான் டெக்ஸ்ட் டேட்டா எனும்போது மட்டும் sequential எனும் வார்த்தை பயன்படுத்தப்படுகிறது. பொதுவாக, பல்வேறு முட்டைகளைப் பெற்று விளங்கும் நியூரல் நெட்வொர்க்கானது, டெக்ஸ்ட் டேட்டா எனும்போது மட்டும் திடீரென, ஒரு டப்பாவுக்கு முன்னும் பின்னும் ஒரு கோடு போட்டு காணப்படும். இது எதனால் நிகழ்கிறது என்பதை அடுத்த பகுதியில் காணலாம்.
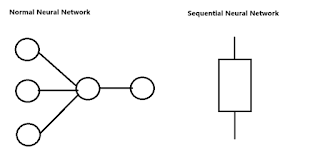
Sequential neural network
ஓட்டப் பந்தயக் களத்தில் உள்ள பல்வேறு track-களுக்கு சமமானது தான் இன்புட் லேயரில் உள்ள நியூரான்கள். அந்த டிராக்குகளில் தயார் நிலையில் நின்று கொண்டிருக்கும் மாணவர்களுக்கு சமமானது தான் நமது டேட்டாக்கள். ட்ரெய்னிங் டேட்டாவில் உள்ள ஒவ்வொரு row-ம், பல்வேறு டிராக்குகளில் அடுத்தடுத்த batch-ல் நின்று கொண்டிருக்கும் மாணவர்களுக்கு சமமானது. விசில் அடித்தவுடன் ஒரே நேரத்தில் முதல் வரிசையில் உள்ள அனைத்து மாணவர்களும் ஓடத் துவங்குவது போல, ட்ரெய்னிங் டேட்டாவில் முதல் row -வில் உள்ள அனைத்து டேட்டாக்களும் ஒரே நேரத்தில் உள் நுழைந்து பிராசஸ் செய்யப்படுவது சாதா நியூரல் நெட்வொர்க் எனப்படும்.
ஓட்டப்பந்தயத்தில் நன்றாக ஓடிய சிறந்த ஐந்து மாணவர்களை தேர்ந்தெடுத்து, ஒரே குழுவாக்கி, Relay ரேஸ் ஓடச் சொல்வது போன்றது சீக்குவென்ஷியல் நியூரல் நெட்வொர்க் என்பது! Relay ரேஸ் எனும்போது, விசில் அடித்தவுடன் அவர்கள் ஐந்து பேரும் ஒரே நேரத்தில் ஓடத் தேவையில்லை. ஏனெனில் இப்போது அவர்களுக்குள் ஒரே குழு என்ற தொடர்பு ஏற்பட்டுவிட்டது. ஆகவே ஒருவர் ஓடி முடித்த பின், மற்றொருவர் என ஒவ்வொருவராக ஓடினால் தான் ஓட்டம் முழுமை பெறும். அதுபோலத்தான் டெக்ஸ்ட் டேட்டா எனும் பொழுது, அவை அனைத்துமே ஒரே குழுவாகி ஒன்றன்பின் ஒன்றாக சென்றால் மட்டுமே அர்த்தம் கிடைக்கும். இதற்குத்தான் சீக்குவென்ஷியல் நியூரல் நெட்வொர்க் என்று பெயர்.
எடுத்துக்காட்டாக பின்வரும் உரைநடைக்கான டோக்கன் மற்றும் ட்ரெய்னிங் டேட்டா பின்வருமாறு அமையும்.
உரை:
“தமிழ்நாடு இந்தியாவின் தெற்கே அமைந்த ஒரு அழகிய மாநிலமாகும். இது பல்வேறு கலாச்சார பாரம்பரியங்களையும், செழிப்பான சாகுபடிமுறையையும் கொண்டுள்ளது. தமிழ்நாட்டின் தலைநகரமான சென்னை, தொழில்நுட்பம் மற்றும் கல்வியில் முன்னணி வகிக்கிறது. மாமல்லபுரம், தஞ்சாவூர் பெரிய கோயில் போன்ற வரலாற்று முக்கியத்துவம் வாய்ந்த இடங்கள் சுற்றுலாப் பயணிகளை ஈர்க்கின்றன. தமிழ்நாட்டின் கலை, இலக்கியம் மற்றும் இசை உலகளாவிய புகழ் பெற்றவை”
டோக்கன்:
{‘தமிழ்நாட்டின்’: 1, ‘மற்றும்’: 2, ‘தமிழ்நாடு’: 3, ‘இந்தியாவின்’: 4, ‘தெற்கே’: 5, ‘அமைந்த’: 6, ‘ஒரு’: 7, ‘அழகிய’: 8, ‘மாநிலமாகும்’: 9, ‘இது’: 10, ‘பல்வேறு’: 11, ‘கலாச்சார’: 12, ‘பாரம்பரியங்களையும்’: 13, ‘செழிப்பான’: 14, ‘சாகுபடிமுறையையும்’: 15, ‘கொண்டுள்ளது’: 16, ‘தலைநகரமான’: 17, ‘சென்னை’: 18, ‘தொழில்நுட்பம்’: 19, ‘கல்வியில்’: 20, ‘முன்னணி’: 21, ‘வகிக்கிறது’: 22, ‘மாமல்லபுரம்’: 23, ‘தஞ்சாவூர்’: 24, ‘பெரிய’: 25, ‘கோயில்’: 26, ‘போன்ற’: 27, ‘வரலாற்று’: 28, ‘முக்கியத்துவம்’: 29, ‘வாய்ந்த’: 30, ‘இடங்கள்’: 31, ‘சுற்றுலாப்’: 32, ‘பயணிகளை’: 33, ‘ஈர்க்கின்றன’: 34, ‘கலை’: 35, ‘இலக்கியம்’: 36, ‘இசை’: 37, ‘உலகளாவிய’: 38, ‘புகழ்’: 39, ‘பெற்றவை’: 40}
ட்ரெய்னிங் டேட்டா:
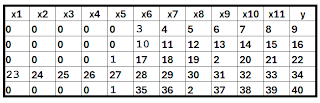
Underlying Data:

பொதுவாக ட்ரெய்னிங் டேட்டாவின் அடுத்தடுத்த feature -களின் டேட்டாக்களுக்கிடையில் எந்த ஒரு தொடர்பும் இருக்காது. அப்படியே இருந்தாலும் கூட, correlation மேட்ரிக்ஸ் என்ற ஒன்றைப் பயன்படுத்தி, அதிக தொடர்புடைய ஃபீச்சர்களை நீக்கி விடுவது பற்றி மெஷின் லேர்னிங் புத்தகத்தில் கண்டோம். ஆனால் டெக்ஸ்ட் டேட்டா எனும்போது மட்டும், அடுத்தடுத்த ஃபீச்சர்களின் டேட்டாக்களுக்கிடையில் உள்ள தொடர்புதான், அதிமுக்கியமாகக் கருத்தில் கொள்ளப்பட வேண்டிய ஒன்றாகும்.
இந்த இடத்தில் போய் சாதா நியூரல் நெட்வொர்க் பயன்படுத்தினால், அது மொத்தமாக உட்சென்று, கண்டபடி வார்த்தைகள் முன்னும் பின்னுமாகி வாக்கியம் குளறுபடியாகிவிடும்.
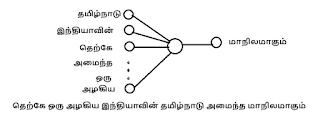
ஆகவே, x1- க்குப் பின் X2, அதற்குப் பின் x3, அதற்குப் பின் x4 என ஒவ்வொன்றாகத் தான் உள்ளே வர வேண்டும். எனவேதான் இதற்கான நியூரல் நெட்வொர்க், sequential எனும் பெயரில் அழைக்கப்படுகிறது. சாதா நியூரல் நெட்வொர்க் ஒவ்வொரு வெக்டராக எடுத்து ப்ராசஸ் செய்யுமெனில், சீக்குவென்ஷியல் நியூரல் நெட்வொர்க், அதற்கும் ஒரு படி மேலே போய், ஒவ்வொரு வெக்டரில் உள்ள elements -ஐயும் ஒவ்வொன்றாக எடுத்து ப்ராசஸ் செய்கிறது. அவை ஒவ்வொன்றாக உள்ளே வரவர அதற்கு ஒரு டைம்ஸ்டாம்ப் ஒட்டப்பட்டு அதே முறையில் வரிசைப்படுத்தி ப்ராசஸ் செய்யப்படுகிறது. இந்த டைம்ஸ்டாம்ப் பொதுவாக t, t+1, t+2…. என மொத்த ஃபீச்சர்ஸின் எண்ணிக்கைக்கு ஏற்ப அமையும்.

எத்தனை ஃபீச்சர்ஸ் இருந்தாலும் அவை ஒன்றன்பின் ஒன்றாகத் தான் உள்ளே வரப்போகிறது என்பதால், இன்புட் லேயரில் நிறைய நியூரான்கள் இருப்பது போன்ற வடிவமைப்பே இதற்குத் தேவையில்லாத ஒன்றாகிவிட்டது. எனவே எல்லா நியூரான்களையும் நீக்கி சீக்குவென்ஷியல் நியூரல் நெட்வொர்க் பின்வருமாறு காட்சியளிக்கிறது.

RNN, LSTM போன்ற அனைத்துமே இத்தகைய sequential () மாடலைப் பயன்படுத்துபவை தான்.
RNN vs LSTM
இவ்விரண்டுமே sequential மாடலுக்கான அல்காரிதம் தான்! ஆனால் நீண்ட நெடிய தொடரை நினைவில் வைத்துக் கொள்வதில் LSTM சிறப்பாகச் செயல்படுகிறது. இவைகளுக்கிடையேயான வித்தியாசத்தை உணர முதலில் ‘படையப்பா’ திரைப்பட நகைச்சுவைக் காட்சியை எடுத்துக் கொள்வோம்.
“படையப்பாவும் அவனது நண்பர்களும் சேர்ந்து குமரேசனுக்குப் பெண்பார்க்கச் சென்று கொண்டிருக்கின்றனர்” எனும் வரியைக் கொடுத்து “மாப்பிள்ளை யார்?” எனக் கேட்டால், “குமரேசன்” என்று சட்டென பதிலளித்து விடும் RNN.
அதுவே, “படையப்பாவும் அவனது நண்பர்களும் குமரேசனுக்குப் பெண்பார்க்கச் சென்று கொண்டிருக்கும் போது, மாப்பிள்ளை இடறி சேற்றில் விழுந்து விடவே, அவரது ஆடை முழுவதும் அழுக்காகிவிட்டதால், பெண் பார்க்கச் செல்லலாமா வேண்டாமா எனும் குழப்பம் அனைவரிடத்திலும் நிலவ, படையப்பா தனது ஆடையைக் கழட்டி மாப்பிள்ளைக்குக் கொடுத்தார்” எனும் ஒரு பெரிய வரியைக் கொடுத்து “மாப்பிள்ளை யார்?” எனக் கேட்டால், RNN குழம்பிவிடும்.
அடுத்தடுத்த வார்த்தைகளை மெமரியில் வைத்துக் கொண்டே வரும்போது, பழைய வார்த்தைகளை RNN மறந்து விடுகிறது. “மாப்பிள்ளை யாருன்னு எங்களுக்கே ஒரே சந்தேகமா இருக்கு, நீயே கேட்டு தெரிஞ்சுக்கோ!” என்று தாமு பதிலளிப்பாரே, அது போல!
LSTM என்பது படையப்பா போல! முக்கியமான விஷயங்களை நினைவில் வைத்துக்கொண்டே வந்து, சட்டென பதிலளிக்கும். இன்னும் சொல்லப்போனால், படையப்பாவை விட புத்திக் கூர்மை உடையது. “மாப்பிள்ளை குமரேசன் தான்! ஆனால் அவர் போட்டிருக்கும் ஆடை என்னுடையது!” என்றுதான் படையப்பா கூட பதிலளிப்பார். எவ்வளவு வற்புறுத்தியும் அவரால் ஆடை பற்றிய விஷயத்தை மறக்கவே முடியாது. ஆனால் LSTM அப்படி அல்ல! முக்கியமான விஷயங்களை நினைவில் வைத்துக் கொள்ளும் பொழுது, மறக்க வேண்டிய விஷயங்களை மறந்தும் விடுகிறது. அதாவது ‘ஆடை மாற்றம்’ எனும் சொல் வரும்பொழுது, ‘படையப்பாவின் ஆடை’ என்பதை மறந்து ‘குமரேசனின் ஆடை’ என்பதை மட்டும் நினைவில் வைத்துக் கொள்கிறது. Forget gate என்பது இந்த வேலையைச் சிறப்பாகச் செய்கிறது.
Long Term Memory loss
மேற்கூறியது போல RNN-க்கு long-term memory loss எனும் பிரச்சனை உள்ளது. ஒரு பெரிய வாக்கியம் எழுதிக் கொண்டிருக்கும் பொழுது, பழைய மெமரியில் ஏதாவது சேமிக்கப்பட்டிருந்தால் அதனை மறந்து விடும். உதாரணத்துக்கு பின்வருமாறு ஒரு பெரிய வாக்கியம் எழுதிக் கொண்டிருக்கிறோமெனில், அடைப்புக் குறிக்குள் உள்ளவாறு ஒவ்வொரு வார்த்தையையும் தனது நினைவில் வைத்துக் கொண்டே வரும். ஆனால் t+20 எனுமிடத்தில், t-1 இல் சேமிக்கப்பட்ட வார்த்தையை இது மறந்திருக்கும்.
“தமிழ்நாடு(t-1), இந்தியாவின்(t) தெற்கே(t+1) அமைந்துள்ள(t+2) ஒரு(t+3) அழகிய(t+4) மாநிலமாக(t+5), அதன்(t+6) கலாச்சாரம்(t+7) மற்றும் (t+8) பாரம்பரியத்திற்குப்(t+9) பெயர்(t+10) பெற்றதுடன்(t+11), தொழில்நுட்ப(t+12) வளர்ச்சியும்(t+13) மிகுந்து(t+14) வருவதால்(t+15), ஒரு(t+16) தனித்துவம்(t+17) மிக்க(t+18) மாநிலமாக(t+19) ___?”
எனவே அடுத்தடுத்ததாக வரவிருக்கும் “தமிழ்நாடு”, “திகழ்கிறது” போன்ற வார்த்தைகளை இதனால் பரிந்துரைக்க இயலாது. இப்பிரச்சனையை தீர்க்கும் பொருட்டு, முக்கியமான key வார்த்தைகளை மட்டும் நினைவில் வைத்துக் கொள்ளும் வகையில், ஒரு long term மெமரியையும் இணைத்து உருவானதே LSTM ஆகும். இதில் அனைத்து வார்த்தைகளும் short-term மெமரியில் சேமிக்கப்படுவதுடன், மிக முக்கியமான வார்த்தைகள் long-term மெமரியிலும் சேமிக்கப்படுகின்றன.

இவ்விரண்டு மெமரிகளுக்கும் இடையே வார்த்தைகள் சென்று வர நான்கு வகையான Gates உள்ளன. அவை,
- Input gate
- Output gate
- Forget gate
- Cell gate
ஆகும். இவற்றைப் பற்றி அடுத்த பகுதியில் காணலாம். Forget gate பற்றி மட்டும் இங்கு காண்போம். மேற்கண்ட வாக்கியத்தைத் தொடர்ந்து, திடீரென கேரளா பற்றிய வாக்கியம் வருகிறதெனில், இதிலுள்ள வார்த்தைகளும் Long-term மெமரியில் சேர்ந்து கொண்டே வரும். ஆனால் ‘கேரளா’ எனும் பெயரை long-term மெமரியில் சேர்க்கும் பொழுதே ‘தமிழ்நாடு’ எனும் பெயரை அது மறந்துவிடும். எடுத்துக்காட்டாக, கீழ்க்கண்டவாறு அடுத்த வாக்கியம் வருகிறதெனில்,
“ஆனால்(t-1) கல்வியறிவு(t) விகிதத்தில்(t+1) கேரளா(t+2) இந்தியாவிலேயே முதல் நிலையிலுள்ள மாநிலமாதலால், உயர்ந்த கல்வி மட்டத்திற்குப் பெயர்(t_10) பெற்ற(t+11) மாநிலமாக(t+12) ___?”
“கேரளா”, “திகழ்கிறது” என்பதைத்தான் பரிந்துரைக்குமே தவிர, தமிழ்நாடு என்பதை மறந்திருக்கும்.

அதாவது, ஒரு விஷயத்தைப் பற்றி பேசிக் கொண்டிருக்கும் பொழுது அதன் தொடர்ச்சியான வார்த்தைகளை நினைவில் வைத்துக் கொண்டே வரும். ஆனால் அடுத்த விஷயத்துக்கு செல்லும் பொழுது, மெமரியும் தன்னை உடனே அடுத்த முக்கிய வார்த்தையால் அப்டேட் செய்து கொள்ளும். எதுவெல்லாம் முக்கிய key வார்த்தைகள், எதுவெல்லாம் அவற்றைத் தழுவி வருகின்ற வார்த்தைகள் என்பதையெல்லாம் அந்தந்த வார்த்தைகளுக்கான Embedding vector – களுக்கிடையே நிகழும் கணக்கீடுகளை வைத்து தானாகக் கண்டுபிடித்து விடும். Embedding பற்றி இனிவரும் பகுதிகளில் விளக்கமாகக் காணலாம்.
Four Gates
Short term மற்றும் Long term மெமரிகளுக்கு இடையே வார்த்தைகள் சென்று வர நான்கு வகையான Gates உள்ளன என்று ஏற்கனவே பார்த்தோம். இவை என்னென்ன வேலைகளுக்காகப் பயன்படுகின்றன? என்னென்ன சூத்திரங்களைப் பயன்படுத்துகின்றன? என்பதையெல்லாம் இப்பகுதியில் காணலாம். Short-term மெமரியில் உள்ளவை hidden state எனவும், Long-term மெமரியில் உள்ளவை cell state அல்லது candidate state எனவும் அழைக்கப்படும்.
- short-term மெமரியில் உள்ள வார்த்தைகளில், எவற்றையெல்லாம் long-term மெமரிக்கு அனுப்பலாம் என்பதைப் பரிந்துரைக்க Input gate உதவுகிறது. ஒவ்வொன்றாக எடுத்து, அதை அனுப்பலாமா? வேண்டாமா? என்பதை முடிவெடுக்க sigmoid ஃபங்க்ஷனையும், அனுப்பலாமெனில் அந்த வார்த்தையை அனுப்புவதற்கு tanh ஃபங்க்ஷனையும் பயன்படுத்துகிறது.
- Output gate என்பதும் அதே இரண்டு ஃபங்க்ஷனைப் பயன்படுத்தி long-term மெமரியில் உள்ளவற்றில் சரியானதைத் தேர்ந்தெடுத்து அவுட்புட் வார்த்தையாக பரிந்துரைக்க உதவுகிறது.
- Cell gate என்பது candidate state-க்குள் இணையவிருக்கும் வார்த்தையை அனுமதித்து உள் அனுப்புகிறது. இதற்கு tanh ஃபங்க்ஷனை மட்டும் பயன்படுத்துகிறது.
- Forget gate என்பது candidate state-இல் இருக்கும் வார்த்தைகளை நினைவில் வைத்துக் கொள்ளலாமா? வேண்டாமா? எனும் முடிவினை மட்டும் எடுப்பதால் sigmoid ஃபங்க்ஷனை மட்டும் பயன்படுத்துகிறது.
Bidirectional Memory
இது RNN, LSTM என இரண்டிலுமே உள்ளது. ஒரு சில சமயங்களில், ஒரு வார்த்தையின் அர்த்தத்தைப் புரிந்து கொள்ள, அதற்கு முந்தைய வார்த்தைகளை நினைவில் வைத்துக் கொள்வதுடன் அதைத்தொடர்ந்து வரப்போகும் வார்த்தைகளையும் நினைவில் வைத்துக் கொள்ள வேண்டும். எடுத்துக்காட்டாக,
- அவனுக்கு கால் வலிக்கிறது.
- அவனுக்கு கால் மணி நேரத்தில் உணவு கொடு.
இதில், முதல் வாக்கியத்தில் உள்ள ‘கால்’ என்பது உடலுறுப்பின் பெயரைக் குறிக்கிறது. இரண்டாவது வாக்கியத்தில் உள்ள ‘கால்’ என்பது கால-நேர அளவினைக் குறிக்கிறது. இந்த இரண்டிலுமே கால் என்பதன் அர்த்தத்தைப் புரிந்து கொள்ள அதைத் தொடர்ந்து வரப்போகும் வார்த்தைகளை நினைவில் வைத்துக் கொள்ள வேண்டியது அவசியம். இதற்கு உதவுவதே Bidirectional மெமரி ஆகும். இந்த Bidirectional மெமரியுடன் ஒரு LSTM மாடல் உருவாக்குவது பற்றி இனிவரும் பகுதிகளில் காணலாம்.