Next Word Prediction
மேற்கண்ட அனைத்தையும் டென்சார் ஃப்ளோவின் ஒரு பகுதியாக விளங்கும் keras மூலம் செய்வது பற்றி இப்பகுதியில் காண்போம்.
- ஒரு வார்த்தை என்பது ஸ்கேலார் போன்றது,
- பல வார்த்தைகளின் தொகுப்பான வாக்கியம் என்பது வெக்டார் ஆகியது,
- பல வாக்கியங்களின் தொகுப்பான உரைநடையானது டென்சார் ஆக மாறியது
என்பது இப்போது நாம் அறிந்ததே! இவைகளுக்கிடையே நிகழும் கணக்கீடுகள் தான் டென்சார் ஃப்ளோ ஆகும். இதில் நியூரல் நெட்வொர்க் உருவாக்கத்திற்கென டென்சார் ஃப்ளோவில் விளங்கும் ஒரு மாடியூல்தான் கீராஸ் என்பது. கீராஸில் உள்ள வெவ்வேறு வகையான லேயர்களைப் பயன்படுத்தி, வெவ்வேறு வகையான மாடல்களை நாம் உருவாக்க முடியும். இவற்றில் LSTM, RNN, Bidirectional LSTM, Stacked LSTM போன்ற சீக்வென்ஷியல் மாடல்களை உருவாக்குவதைப் பற்றி இப்பகுதியில் காண்போம்.
LSTM
தமிழ்நாடு பற்றிய ஐந்தே ஐந்து வரிகளைக் கொடுத்து, பயிற்சியளித்து, ஒரு எளிமையான LSTM மாடலை உருவாக்குவதற்கான நிரல் பின்வருமாறு.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| import numpy as np | |
| import tensorflow as tf | |
| from tensorflow.keras.preprocessing.text import Tokenizer | |
| from tensorflow.keras.models import Sequential | |
| from tensorflow.keras.layers import Embedding, LSTM, Dense, Bidirectional, SimpleRNN | |
| from tensorflow.keras.preprocessing.sequence import pad_sequences | |
| x = "தமிழ்நாடு இந்தியாவின் தெற்கே அமைந்த ஒரு அழகிய மாநிலமாகும். இது பல்வேறு கலாச்சார பாரம்பரியங்களையும், செழிப்பான சாகுபடிமுறையையும் கொண்டுள்ளது. தமிழ்நாட்டின் தலைநகரமான சென்னை, தொழில்நுட்பம் மற்றும் கல்வியில் முன்னணி வகிக்கிறது. மாமல்லபுரம், தஞ்சாவூர் பெரிய கோயில் போன்ற வரலாற்று முக்கியத்துவம் வாய்ந்த இடங்கள் சுற்றுலாப் பயணிகளை ஈர்க்கின்றன. தமிழ்நாட்டின் கலை, இலக்கியம் மற்றும் இசை உலகளாவிய புகழ் பெற்றவை" | |
| tokens = Tokenizer() | |
| tokens.fit_on_texts([x]) | |
| dictionary = tokens.word_index | |
| x_n_grams = [] | |
| for line in x.split('.'): | |
| line_tokens = tokens.texts_to_sequences([line])[0] | |
| for i in range(1, len(line_tokens)): | |
| n_grams = line_tokens[:i+1] | |
| x_n_grams.append(n_grams) | |
| max_line_len = max([len(i) for i in x_n_grams]) | |
| training_data = np.array(pad_sequences(x_n_grams, maxlen=max_line_len, padding='pre')) | |
| train_X = training_data[:, :-1] | |
| train_y = training_data[:, -1] | |
| total_words = len(dictionary) + 1 | |
| y = np.array(tf.keras.utils.to_categorical(train_y, num_classes=total_words)) | |
| model = Sequential() | |
| model.add(Embedding(total_words, 100, input_length=max_line_len-1)) | |
| model.add(LSTM(150)) | |
| model.add(Dense(total_words, activation='softmax')) | |
| model.build(input_shape=(None, max_line_len-1)) | |
| print(model.summary()) | |
| model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) | |
| model.fit(train_X, y, epochs=100, verbose=1) | |
| input_text = "தமிழ்நாடு" | |
| predict_next_words= 3 | |
| for _ in range(predict_next_words): | |
| input_token = tokens.texts_to_sequences([input_text])[0] | |
| input_x = pad_sequences([input_token], maxlen=max_line_len-1, padding='pre') | |
| predicted = np.argmax(model.predict(input_x), axis=-1) # Greedy. tensorflow.random.categorical(input_token,num_samples=1) for sampling for beam search | |
| output_word = "" | |
| for word, index in tokens.word_index.items(): | |
| if index == predicted: | |
| output_word = word | |
| break | |
| input_text += " " + output_word | |
| print(input_text) | |
| """ | |
| In between Embedding and output Layers | |
| RNN: | |
| model.add(SimpleRNN(150)) | |
| Bidirectional LSTM: | |
| model.add(Bidirectional(LSTM(150, return_sequences=True))) | |
| model.add(LSTM(100)) | |
| Stacked LSTM: | |
| model.add(Bidirectional(LSTM(150, return_sequences=True))) | |
| model.add(Bidirectional(LSTM(100, return_sequences=True))) | |
| model.add(LSTM(64)) | |
| """ |
நிரலுக்கான விளக்கம்:
படி 1:
முதலில் ஒவ்வொரு வார்த்தைக்கும் ஒரு டோக்கன் அளிக்கப்படுகிறது.
Tokenizer().fit_on_texts() என்பது இந்த வேலையைச் செய்கிறது. கொடுக்கப்பட்டுள்ள 42 வார்த்தைகளில் இரு வார்த்தைகள் (‘தமிழ்நாட்டின்’, ‘மற்றும்’) இருமுறை இடம்பெற்றுள்ளதால் 40 டோக்கன் வரை அளித்துள்ளது. word_index எனும் ஃபங்க்ஷன், எந்த வார்த்தைக்கு எந்த டோக்கன் கொடுக்கப்பட்டுள்ளது என்பதை வெளிப்படுத்தும்.
print (tokens.word_index)
{‘தமிழ்நாட்டின்’: 1, ‘மற்றும்’: 2, ‘தமிழ்நாடு’: 3, ‘இந்தியாவின்’: 4, ‘தெற்கே’: 5, ‘அமைந்த’: 6, ‘ஒரு’: 7, ‘அழகிய’: 8, ‘மாநிலமாகும்’: 9, ‘இது’: 10, ‘பல்வேறு’: 11, ‘கலாச்சார’: 12, ‘பாரம்பரியங்களையும்’: 13, ‘செழிப்பான’: 14, ‘சாகுபடிமுறையையும்’: 15, ‘கொண்டுள்ளது’: 16, ‘தலைநகரமான’: 17, ‘சென்னை’: 18, ‘தொழில்நுட்பம்’: 19, ‘கல்வியில்’: 20, ‘முன்னணி’: 21, ‘வகிக்கிறது’: 22, ‘மாமல்லபுரம்’: 23, ‘தஞ்சாவூர்’: 24, ‘பெரிய’: 25, ‘கோயில்’: 26, ‘போன்ற’: 27, ‘வரலாற்று’: 28, ‘முக்கியத்துவம்’: 29, ‘வாய்ந்த’: 30, ‘இடங்கள்’: 31, ‘சுற்றுலாப்’: 32, ‘பயணிகளை’: 33, ‘ஈர்க்கின்றன’: 34, ‘கலை’: 35, ‘இலக்கியம்’: 36, ‘இசை’: 37, ‘உலகளாவிய’: 38, ‘புகழ்’: 39, ‘பெற்றவை’: 40}
படி 2:
texts_to_sequences() என்பது ஒவ்வொரு வாக்கியத்தையும் டோக்கன்களைப் பெற்று விளங்கும் வெக்டராக மாற்றுகிறது.
print(line)
print(line_tokens)
தமிழ்நாடு இந்தியாவின் தெற்கே அமைந்த ஒரு அழகிய மாநிலமாகும்
[3, 4, 5, 6, 7, 8, 9]
இது பல்வேறு கலாச்சார பாரம்பரியங்களையும், செழிப்பான சாகுபடிமுறையையும் கொண்டுள்ளது
[10, 11, 12, 13, 14, 15, 16]
தமிழ்நாட்டின் தலைநகரமான சென்னை, தொழில்நுட்பம் மற்றும் கல்வியில் முன்னணி வகிக்கிறது
[1, 17, 18, 19, 2, 20, 21, 22]
மாமல்லபுரம், தஞ்சாவூர் பெரிய கோயில் போன்ற வரலாற்று முக்கியத்துவம் வாய்ந்த இடங்கள் சுற்றுலாப் பயணிகளை ஈர்க்கின்றன
[23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34]
தமிழ்நாட்டின் கலை, இலக்கியம் மற்றும் இசை உலகளாவிய புகழ் பெற்றவை
[1, 35, 36, 2, 37, 38, 39, 40]
படி 3:
பின், ஒரு வாக்கியத்துக்கான ஒரு வெக்டர் என்பது incremental முறையில் கொஞ்சம் கொஞ்சமாக வார்த்தைகளை அதிகரிக்கும் பல்வேறு வெக்டர்களாக மாற்றப்படுகின்றன.
print(n_grams)
[3, 4]
[3, 4, 5]
[3, 4, 5, 6]
[3, 4, 5, 6, 7]
[3, 4, 5, 6, 7, 8]
[3, 4, 5, 6, 7, 8, 9]
[10, 11]
[10, 11, 12]
[10, 11, 12, 13]
[10, 11, 12, 13, 14]
[10, 11, 12, 13, 14, 15]
[10, 11, 12, 13, 14, 15, 16]
[1, 17]
[1, 17, 18]
[1, 17, 18, 19]
[1, 17, 18, 19, 2]
[1, 17, 18, 19, 2, 20]
[1, 17, 18, 19, 2, 20, 21]
[1, 17, 18, 19, 2, 20, 21, 22]
[23, 24]
[23, 24, 25]
[23, 24, 25, 26]
[23, 24, 25, 26, 27]
[23, 24, 25, 26, 27, 28]
[23, 24, 25, 26, 27, 28, 29]
[23, 24, 25, 26, 27, 28, 29, 30]
[23, 24, 25, 26, 27, 28, 29, 30, 31]
[23, 24, 25, 26, 27, 28, 29, 30, 31, 32]
[23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33]
[23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33,34]
[1, 35]
[1, 35, 36]
[1, 35, 36, 2]
[1, 35, 36, 2, 37]
[1, 35, 36, 2, 37, 38]
[1, 35, 36, 2, 37, 38, 39]
[1, 35, 36, 2, 37, 38, 39, 40]
படி 4:
இவை அனைத்தையும் ஒரே டைமென்ஷனில் அமைக்க, இருப்பதிலேயே பெரிய வெக்டரின் அளவு கண்டுபிடிக்கப்பட்டு அதே அளவில் மற்ற அனைத்தும் மாற்றப்படுகின்றன. pad_sequences() மூலம் காலி இடங்களில் ஜீரோ நிரப்பப்படுகிறது. பின், இந்த தனித்தனி வெக்டர்கள் அனைத்தும் ஒரு பெரிய வெக்டருக்குள் இடப்பட்டு 2D ட்ரெய்னிங் டேட்டாவாக மாற்றப்படுகின்றது.
print (training_data)
[[ 0 0 0 0 0 0 0 0 0 0 3 4]
[ 0 0 0 0 0 0 0 0 0 3 4 5]
[ 0 0 0 0 0 0 0 0 3 4 5 6]
[ 0 0 0 0 0 0 0 3 4 5 6 7]
[ 0 0 0 0 0 0 3 4 5 6 7 8]
[ 0 0 0 0 0 3 4 5 6 7 8 9]
[ 0 0 0 0 0 0 0 0 0 0 10 11]
[ 0 0 0 0 0 0 0 0 0 10 11 12]
[ 0 0 0 0 0 0 0 0 10 11 12 13]
[ 0 0 0 0 0 0 0 10 11 12 13 14]
[ 0 0 0 0 0 0 10 11 12 13 14 15]
[ 0 0 0 0 0 10 11 12 13 14 15 16]
[ 0 0 0 0 0 0 0 0 0 0 1 17]
[ 0 0 0 0 0 0 0 0 0 1 17 18]
[ 0 0 0 0 0 0 0 0 1 17 18 19]
[ 0 0 0 0 0 0 0 1 17 18 19 2]
[ 0 0 0 0 0 0 1 17 18 19 2 20]
[ 0 0 0 0 0 1 17 18 19 2 20 21]
[ 0 0 0 0 1 17 18 19 2 20 21 22]
[ 0 0 0 0 0 0 0 0 0 0 23 24]
[ 0 0 0 0 0 0 0 0 0 23 24 25]
[ 0 0 0 0 0 0 0 0 23 24 25 26]
[ 0 0 0 0 0 0 0 23 24 25 26 27]
[ 0 0 0 0 0 0 23 24 25 26 27 28]
[ 0 0 0 0 0 23 24 25 26 27 28 29]
[ 0 0 0 0 23 24 25 26 27 28 29 30]
[ 0 0 0 23 24 25 26 27 28 29 30 31]
[ 0 0 23 24 25 26 27 28 29 30 31 32]
[ 0 23 24 25 26 27 28 29 30 31 32 33]
[23 24 25 26 27 28 29 30 31 32 33 34]
[ 0 0 0 0 0 0 0 0 0 0 1 35]
[ 0 0 0 0 0 0 0 0 0 1 35 36]
[ 0 0 0 0 0 0 0 0 1 35 36 2]
[ 0 0 0 0 0 0 0 1 35 36 2 37]
[ 0 0 0 0 0 0 1 35 36 2 37 38]
[ 0 0 0 0 0 1 35 36 2 37 38 39]
[ 0 0 0 0 1 35 36 2 37 38 39 40]]
படி 5:
ஒவ்வொரு வெக்டரிலும் கடைசி வார்த்தை ப்ரெடிக்ட் செய்யப்பட வேண்டியதாகவும், அதற்கு முந்தைய வார்த்தைகள் ப்ரெடிக்க்ஷனுக்கு உதவுவதாகவும் வைத்து ட்ரெய்னிங் டேட்டா உருவாக்கப்படுகிறது.
print (train_X)
[[ 0 0 0 0 0 0 0 0 0 0 3]
[ 0 0 0 0 0 0 0 0 0 3 4]
[ 0 0 0 0 0 0 0 0 3 4 5]
[ 0 0 0 0 0 0 0 3 4 5 6]
[ 0 0 0 0 0 0 3 4 5 6 7]
[ 0 0 0 0 0 3 4 5 6 7 8]
[ 0 0 0 0 0 0 0 0 0 0 10]
[ 0 0 0 0 0 0 0 0 0 10 11]
[ 0 0 0 0 0 0 0 0 10 11 12]
[ 0 0 0 0 0 0 0 10 11 12 13]
[ 0 0 0 0 0 0 10 11 12 13 14]
[ 0 0 0 0 0 10 11 12 13 14 15]
[ 0 0 0 0 0 0 0 0 0 0 1]
[ 0 0 0 0 0 0 0 0 0 1 17]
[ 0 0 0 0 0 0 0 0 1 17 18]
[ 0 0 0 0 0 0 0 1 17 18 19]
[ 0 0 0 0 0 0 1 17 18 19 2]
[ 0 0 0 0 0 1 17 18 19 2 20]
[ 0 0 0 0 1 17 18 19 2 20 21]
[ 0 0 0 0 0 0 0 0 0 0 23]
[ 0 0 0 0 0 0 0 0 0 23 24]
[ 0 0 0 0 0 0 0 0 23 24 25]
[ 0 0 0 0 0 0 0 23 24 25 26]
[ 0 0 0 0 0 0 23 24 25 26 27]
[ 0 0 0 0 0 23 24 25 26 27 28]
[ 0 0 0 0 23 24 25 26 27 28 29]
[ 0 0 0 23 24 25 26 27 28 29 30]
[ 0 0 23 24 25 26 27 28 29 30 31]
[ 0 23 24 25 26 27 28 29 30 31 32]
[23 24 25 26 27 28 29 30 31 32 33]
[ 0 0 0 0 0 0 0 0 0 0 1]
[ 0 0 0 0 0 0 0 0 0 1 35]
[ 0 0 0 0 0 0 0 0 1 35 36]
[ 0 0 0 0 0 0 0 1 35 36 2]
[ 0 0 0 0 0 0 1 35 36 2 37]
[ 0 0 0 0 0 1 35 36 2 37 38]
[ 0 0 0 0 1 35 36 2 37 38 39]]
print (train_y)
[ 4 5 6 7 8 9 11 12 13 14 15 16 17 18 19 2 20 21 22 24 25 26 27 28
29 30 31 32 33 34 35 36 2 37 38 39 40]
படி 6:
பின்னர் ப்ரெடிக்ட் செய்யப்பட வேண்டியது to_categorical() மூலம் one-hot encoding செய்யப்படுகிறது. பொதுவாக ஒவ்வொரு வார்த்தையும் இதில் ஒரு முறை வந்து விடுவதால் num_classes=total_words எனக் கொடுக்கப்பட்டுள்ளது.
print (y)
[[0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
…………..
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]]
படி 7:
அடுத்ததாக நியூரல் நெட்வொர்க்கை வரையறுக்க வேண்டும். பொதுவாக நியூரல் நெட்வொர்க் என்பது மூன்று லேயர்களைக் கொண்டது. அவை இன்புட், அவுட்புட் மற்றும் இடையில் உள்ள ஆக்டிவேஷன் லேயர்கள்.
இங்கு இன்புட் வேலைக்கென Embedding லேயர் பயன்படுகிறது. இது நமது இன்புட் வெக்டரில் உள்ள ஒவ்வொரு வார்த்தைக்கும், 100 டைமென்ஷன் கொண்ட இன்னொரு வெக்டரை உருவாக்குகிறது. இதுவே எம்பெடிங் வெக்டர் ஆகும். இதுவரை டோக்கன் செய்யப்பட்ட வார்த்தைகளைத் தானே வெக்டர் எனக் கூறினோம். இதென்ன திடீரென முளைக்கும் எம்பெடிங் வெக்டர் என்று யோசிக்கிறீர்களா? NLP பொறுத்தவரையில் எதைச் செய்தாலும் அதில் எம்பெடிங் வெக்டர் என்ற ஒன்று உருவாகாமல் செய்ய முடியாது. இதுதான் ஒரு வார்த்தையின் அர்த்தத்தைப் புரிந்து கொண்டு பிராசஸ் செய்ய உதவும் மிக முக்கிய featured வெக்டர் ஆகும். உதாரணத்துக்கு ‘அந்தப் பொண்ணு லவ் பண்ற பையன் யாருன்னு எனக்குத் தெரியும்; ஆனால் அவன் பெயரை நான் சொல்ல மாட்டேன்” எனக் கூறி, “நேத்து கூட அவங்க ரெண்டு பேரையும் திருவிழால ஒன்னா பார்த்தேன்; காலேஜுக்கு கூட ஒன்னா ட்ரெயின்ல போறாங்கன்னு கேள்விப்பட்டேன்; அவன் அம்மா நாலு இடத்துல பத்து பாத்திரம் தேச்சு படிக்க வச்சா, இப்படித் திரியுறானே!” என்றெல்லாம் கூறி அவன் யார் என்பதை நாமே கண்டுபிடிக்கும் வகையில் செய்து விடுவார்கள். இதே வேலையைத்தான் எம்பெடிங் வெக்டரில் உள்ள 100 features-ம் செய்கின்றன.
Embedding என்றால் ‘பொதித்து வைத்தல்’ என்று பொருள். ஒரு கைப்பிடி எனும் fixed size கொண்ட லட்டுக்குள் முந்திரியும் திராட்சையும் பொதித்து வைக்கப்படுவது போல, 100 எனும் fixed size கொண்ட வெக்டருக்குள் ஒரு வார்த்தையைக் கண்டுபிடிப்பதற்கான பல்வேறு அம்சங்கள் பொதித்து வைக்கப்படுவதால் இது இப்பெயரில் அழைக்கப்படுகிறது. இதில் உள்ள சீரான எண்களின் வழியே, நமது வார்த்தை தொடர்பான விவரங்கள் (semantic information & nuanced features) பொதித்து வைக்கப்படுகின்றன. இது எவ்வாறு நிகழ்கிறது என்பதை பிறகு பார்க்கலாம். இப்போதைக்கு, சாதாரண இன்டெக்ஸ் மூலம் குறிக்கப்படுகின்ற வார்த்தைகளை அப்படியே பயிற்சிக்கு அனுப்பாமல், எம்பெடிங் வெக்டரை உருவாக்கி நெட்வொர்க்குக்குள் அனுப்புகிறது என்பதை மட்டும் புரிந்து கொள்வோம்.
அடுத்ததாக பல்வேறு ஆக்டிவேஷன் யூனிட்களைப் பெற்று விளங்கும் லேயராக எல்.எஸ்.டி.எம் வரையறுக்கப்படுகிறது. LSTM(150) என்பதில் அடைப்புக் குறிக்குள் உள்ள எண்ணிக்கை அதில் உள்ள நியூரான்களின் எண்ணிக்கையைக் குறிக்கிறது. இது போன்ற இடை லேயர்கள், ஒன்றுக்கும் மேற்பட்ட எண்ணிக்கையில் அமைந்தால் அதுவே Deep நியூரல் நெட்வொர்க் ஆகும். இங்கு உள்ளது சிம்பிள் நியூரல் நெட்வொர்க். அதிக அளவு நியூரான்கள் இதில் காணப்பட்டாலும், இதனை Dense லேயர் எனக் கூறலாமே தவிர deep நியூரல் நெட்வொர்க் எனக் கூற முடியாது.
கடைசியாக softmax மூலம் மல்டி கிளாஸ் கிளாசிபிகேஷன் செய்வதற்கு ஏதுவாக, ஒரு அவுட்புட் லேயர் வரையறுக்கப்படுகிறது. நமது vocabulary-யில் உள்ள 41 வார்த்தைகளுக்கும் ஒரு நியூரான் என அதிக நியூரான்களைப் பெற்று விளங்கும் Dense லேயராக இது வரையறுக்கப்படுகிறது.
படி 8:
குறைந்தபட்சம் மூன்று லேயர்களைக் கொண்ட ஒரு நெட்வொர்க்கை வரையறுத்த பின் build() மூலம் அது உருவாக்கப்படுகிறது. பின் summary() எனக் கொடுத்தால் ஒரு சில metrics வெளிப்படும்.
பொதுவாக ஒரு மெஷின் லேர்னிங் மாடலை பற்றிப் பேசும் பொழுது, அது எத்தனை மில்லியன்/பில்லியன் பெராமீட்டர்களைக் கொண்டது எனக் கூறுவது வழக்கம். ஏனெனில் அதை வைத்துத்தான் அதன் திறன் முடிவு செய்யப்படுகிறது. அதற்காக அதிக பெராமீட்டர்கள் கொண்டது அதிக திறனுள்ளது என்று அர்த்தமில்லை. அந்த மாடலைப் பற்றிய ஒரு பொதுவான ஐடியா மற்றும் அதன் computational power போன்ற விஷயங்களைத் தெரிந்து கொள்வதற்கு இந்த சம்மரி ஒரு வாய்ப்பாக அமைகிறது.
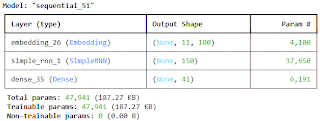
இங்கு நாம் உருவாக்கிய மாடலுக்கான சம்மரி பின்வருமாறு.
print(model.summary())

மூன்று லேயர்கள், அதன் வடிவம் மற்றும் பெராமீட்டர்களின் எண்ணிக்கை மேற்கண்டவாறு வெளிப்பட்டுள்ளது.
Output Shape
11 elements கொண்ட நமது இன்புட் வெக்டரில் உள்ள ஒவ்வொரு வார்த்தையும் 100 elements-ஆக மாறப் போவதால், ஒவ்வொரு வெக்டரும் 11 rows * 100 columns-ஆக மாற்றப்படும். மொத்தம் எத்தனை வெக்டர்கள் எனுமிடத்தில் None என்பது வெளிப்பட்டுள்ளது. இதன் மூலமாக எவ்வளவு டேட்டா வேண்டுமானாலும் இருக்கலாம் என்று அர்த்தம். ஆனால், ஒவ்வொரு லேயரிலும் செலுத்தப்படும் டேட்டாவின் வடிவம் மட்டும் நியூரான்களின் எண்ணிக்கைக்கு ஏற்ப அமைவதால், அம்மதிப்பு மட்டும் அனைத்து லேயரிலும் வெளிப்பட்டுள்ளது.
Param #
அடுத்ததாக பெராமீட்டர்களின் எண்ணிக்கை. இதைப் புரிந்து கொள்வதற்கு முன்னர், ஒரு சிறிய நெட்வொர்க்கில் இருக்கும் பெராமீட்டர்களின் எண்ணிக்கையைப் பார்ப்போம். நான்கே நான்கு features- ஐ வைத்துக் கொண்டு மூன்று வகையான மதிப்புகளின் கீழ் வகைப்படுத்த உதவும் நியூரல் நெட்வொர்க்கின் வரைபடம் பின்வருமாறு.
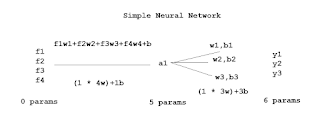 இங்கு ஒவ்வொரு feature-க்கும் ஒரு வெயிட் மற்றும் மொத்தமாக ஒரு பயாஸ் என 5 பெராமீட்டர்கள் உருவாக்கப்பட்டுள்ளதை கண்ணால் கண்டே சொல்லி விட முடியும். அதேபோல அவுட்புட்டில் உள்ள மூன்று வகைகளுக்கும் ஒரு வெயிட் மற்றும் ஒரு பயாஸ் விகிதம் மொத்தம் 6 பெராமீட்டர்கள் உருவாக்கப்பட்டுள்ளதைக் காணலாம். ஆனால் இதைக் கணக்கிடுவதற்கான ஒரு சூத்திரத்தை உருவாக்கினால் மட்டுமே நம்மால் பெரிய மாடலுக்கு மாடலுக்கான பெராமீட்டர்களை கணக்கிடுவதற்கு இலகுவாக இருக்கும். இது பின்வருமாறு.
இங்கு ஒவ்வொரு feature-க்கும் ஒரு வெயிட் மற்றும் மொத்தமாக ஒரு பயாஸ் என 5 பெராமீட்டர்கள் உருவாக்கப்பட்டுள்ளதை கண்ணால் கண்டே சொல்லி விட முடியும். அதேபோல அவுட்புட்டில் உள்ள மூன்று வகைகளுக்கும் ஒரு வெயிட் மற்றும் ஒரு பயாஸ் விகிதம் மொத்தம் 6 பெராமீட்டர்கள் உருவாக்கப்பட்டுள்ளதைக் காணலாம். ஆனால் இதைக் கணக்கிடுவதற்கான ஒரு சூத்திரத்தை உருவாக்கினால் மட்டுமே நம்மால் பெரிய மாடலுக்கு மாடலுக்கான பெராமீட்டர்களை கணக்கிடுவதற்கு இலகுவாக இருக்கும். இது பின்வருமாறு.
- மொத்தம் எத்தனை ஆக்டிவேஷன் யூனிட்கள் உள்ளதோ அதன் எண்ணிக்கை, இன்புட் லேயரில் உள்ள நியூரான்களின் எண்ணிக்கையால் பெருக்கப்பட்டு, ஆக்டிவேஷன் யூனிட்களின் எண்ணிக்கையால் கூட்டப்படுவது – ஆக்டிவேஷன் லேயருக்கான பெராமீட்டர்கள் ஆகும்.
- மொத்தம் எத்தனை ஆக்டிவேஷன் யூனிட்கள் உள்ளதோ அதன் எண்ணிக்கை, அவுட்புட் லேயரில் உள்ள நியூரான்களின் எண்ணிக்கையால் பெருக்கப்பட்டு, அதே எண்ணிக்கையால் கூட்டப்படுவது – அவுட்புட் லேயருக்கான பெராமீட்டர்கள் ஆகும்
இந்த சூத்திரத்தை இரண்டு ஆக்டிவேஷன் யூனிட் கொண்ட நெட்வொர்க்குக்கு பொருத்திப் பார்ப்போம்.
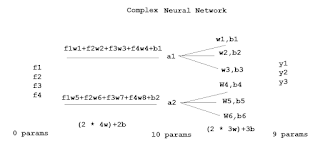 நாம் எதிர்பார்த்தது போலவே ஒழுங்காக வேலை செய்கிறது.
நாம் எதிர்பார்த்தது போலவே ஒழுங்காக வேலை செய்கிறது.
இப்போது நமது நியூரல் நெட்வொர்க்குக்கு பொருத்திப் பார்ப்போம்.
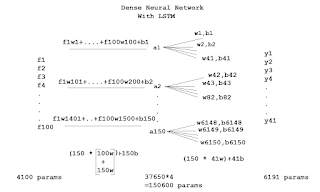
இதில் இரண்டு வித்தியாசங்கள் உள்ளதை கவனிக்கவும்.
- முதலாவது, இன்புட் லேயருக்கான 4100 பெராமீட்டர்கள். இது வேறெந்த நியூரல் நெட்வொர்க்கிலும் கிடையாது. ஏனெனில் ஒவ்வொரு வார்த்தையையும், 100 டைமென்ஷன் கொண்ட வெக்டராக மாற்றப்போவதால், அவைகளுக்கான பெராமீட்டர்களே இவை! மொத்தம் 41 வார்த்தைகள் என்பதால் 4100 பெராமீட்டர்களைக் கொண்டுள்ளது.
- அடுத்ததாக ஆக்டிவேஷன் லேயருக்கான சூத்திரமானது, [150 * (100+150)w] + 150b = 37,650 என அமைந்துள்ளது. பொதுவாக இவ்விரண்டையும் நாம் கூட்டுவது கிடையாது. ஆனால் சீக்வென்ஷியல் எனும் பொழுது மட்டும், வெளிவரும் அவுட்புட் மீண்டும் இன்புட்டாக உள் நுழைவதால் அவை கூட்டப்படுகின்றன. மொத்தம் 4 gates வழியே அவை சென்று வருவதால், அம்மதிப்பு நான்கால் பெருக்கப்பட்டு 150600 பெராமீட்டர்களை வெளிப்படுத்தியுள்ளது.
இவ்வாறாக, ஒவ்வொரு லேயரிலும் உருவாக்கப்படும் பெராமீட்டர்களின் கூட்டுத்தொகையே இந்த மாடலுக்கான மொத்த பெராமீட்டர்கள் ஆகும்.

4100+150600 +6191 = 160,891. அடைப்புக்குறிக்குள் உள்ளது அவை எடுத்துக் கொள்ளும் மெமரியின் அளவு ஆகும்.
Non-trainable params
பெராமீட்டர் என்றாலே அவை பயிற்சியின் போது தன்னை அப்டேட் செய்து கொள்பவை தானே! அதிலென்ன Non-trainable என்று யோசிக்கிறீர்களா? Transfer Learning என்பதில் இது போன்றதொரு கான்செப்ட் உண்டு. ஒரு சில pre-trained மாடல்களை எடுத்து, நம்முடைய டேட்டாவுக்கு ஏற்றார் போல பயிற்சி அளித்து மாற்றும்போது, அதிலுள்ள அனைத்து பெராமீட்டர்களும் தன்னை அப்டேட் செய்து கொள்வதில்லை. ஒரு சில frozen லேயரில் உள்ளவை, broader knowledge மூலம் தாங்கள் திருத்திக் கொண்டுள்ள பெராமீட்டர்களை அப்படியே தக்க வைத்துக் கொள்ளும். எக்காரணம் கொண்டும் அவற்றை நாம் அளிக்கின்ற சிறிய டேட்டாவுக்கு ஏற்றார் போல மாற்றாது. கடைசி ஒரு சில லேயரில் உள்ளவற்றை மட்டும் நம்முடைய புதிய டேட்டாவுக்கு ஏற்றார் போல திருத்திக் கொண்டு செயல்படும். அதைப்போல நாம் உருவாக்கியுள்ள மாடலில் ஏதாவது Frozen layer இருக்கிறதா என்பதையே இந்த Non-trainable params என்பது குறிக்கிறது. இங்கு அது போல எதுவும் இல்லாததால், அதன் எண்ணிக்கை 0 என வெளிப்பட்டுள்ளது.
Embedding செய்வதற்காக word2vec போன்ற ஏதாவதொரு pretrained மாடலைப் பயன்படுத்தினால், அப்போது இந்த Non-trainable params என்பது ஒரு குறிப்பிட்ட எண்ணிக்கையிலான பெராமீட்டர்களைக் கொண்டிருக்கும். அவை word2vec மாடலுக்கான frozen பெராமீட்டர் என்று அர்த்தம். இதை பற்றிப் பின்னர் பார்க்கலாம்.
படி 9:
அடுத்ததாக, நாம் உருவாக்கிய நெட்வொர்க்குக்கு பல்வேறு தவணைகளில் (epochs) பயிற்சி அளிக்க வேண்டும். ஒவ்வொரு தவணையிலும் அதன் திறனை அதிகரிப்பதற்கும், சோதிப்பதற்கும் பயன்படும் விஷயங்களை கொடுத்துத் தொகுப்பதே compile ஆகும். உதாரணத்துக்கு, நாம் யாருக்காவது கடன் கொடுத்தால் அவர் பல்வேறு தவணைகளில் திருப்பித் தருவார் அல்லவா! அப்போது பணம் வரவர நம் கையில் வந்து சேரும் தொகை அதிகரித்துக் கொண்டே வந்து, கடன் தொகை குறைந்து கொண்டே வருமே! அதைப் போல, இங்கு நூறு தவணைகளில் நம்முடைய டேட்டாவுக்கு ஏற்றவாறு பெராமீட்டர் திருத்தப்படும் நிகழ்வில், அதன் திறன் அதிகரித்துக் கொண்டே வந்து இழப்பு குறைவதைக் காணலாம்.
model.fit(train_X, y, epochs=100, verbose=1)
Epoch 1/100
2/2 ━━━━━━ 2s 32ms/step – accuracy: 0.9716 – loss: 0.5210
Epoch 2/100
2/2 ━━━━━━ 0s 33ms/step – accuracy: 0.9716 – loss: 0.5516
Epoch 3/100
2/2 ━━━━━━ 0s 36ms/step – accuracy: 0.9716 – loss: 0.4994
………………
Epoch 17/100
2/2 ━━━━━━ 0s 53ms/step – accuracy: 0.9820 – loss: 0.3285
Epoch 18/100
2/2 ━━━━━━ 0s 34ms/step – accuracy: 0.9820 – loss: 0.3301
……………….
Epoch 55/100
2/2 ━━━━━━━ 0s 34ms/step – accuracy: 0.9716 – loss: 0.1603
Epoch 56/100
2/2 ━━━━━━━ 0s 36ms/step – accuracy: 0.9716 – loss: 0.1600
Epoch 57/100
2/2 ━━━━━━━ 0s 41ms/step – accuracy: 0.9820 – loss: 0.1518
………………..
Epoch 78/100
2/2 ━━━━━━━ 0s 33ms/step – accuracy: 0.9716 – loss: 0.1182
Epoch 79/100
2/2 ━━━━━━━ 0s 34ms/step – accuracy: 0.9716 – loss: 0.1136
…………………
Epoch 98/100
2/2 ━━━━━━━ 0s 33ms/step – accuracy: 0.9716 – loss: 0.0907
Epoch 99/100
2/2 ━━━━━━━ 0s 34ms/step – accuracy: 0.9716 – loss: 0.0969
Epoch 100/100
2/2 ━━━━━━━ 0s 36ms/step – accuracy: 0.9820 – loss: 0.0857
படி 10:
கடைசியாக, ஒரு வார்த்தையைக் கொடுத்து, அதைத்தொடர்ந்து வரும் மூன்று வார்த்தைகளை ப்ரெடிக்ட் செய்யக் கூறினோமேயானால்,
- ட்ரெய்னிங் கொடுத்த அளவில் அந்த வார்த்தைக்கான வெக்டரை உருவாக்கி,
- பொருத்தமான அடுத்த வார்த்தையைத் தேர்வு செய்கிறது.
input_text = “தமிழ்நாடு”
predict_next_words= 3
print(input_token)
print(input_text)
[3]
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 218ms/step
[3, 4]
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 39ms/step
[3, 4, 5]
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 38ms/step
தமிழ்நாடு இந்தியாவின் தெற்கே அமைந்த
Bidirectional LSTM
மேற்கண்ட அதே புரோகிராமில் கீழ்க்கண்ட இடத்தில் உள்ள வரியை மட்டும் மாற்றினால், அதுவே Bidirectional LSTM மாடலுக்கானது.
model.add(Embedding(total_words, 100, input_length=max_line_len-1))
model.add(Bidirectional(LSTM(150, return_sequences=True)))
model.add(LSTM(100))
Bidirectional எனும்போது அதன் பெராமீட்டர் மதிப்பு இரண்டால் பெருக்கப்படுவதைக் காணலாம்.

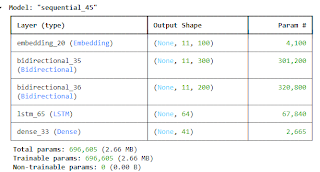
Stacked LSTM
ஒன்றுக்கும் மேற்பட்ட Bidirectional லேயர்களைக் கொண்டது Stacked LSTM ஆகும். மேற்கண்ட அதே புரோகிராமில் கீழ்க்கண்ட இடத்தில் உள்ள வரியை மட்டும் மாற்றவும்!
model.add(Embedding(total_words, 100, input_length=max_line_len-1))
model.add(Bidirectional(LSTM(150, return_sequences=True)))
model.add(Bidirectional(LSTM(100, return_sequences=True)))
model.add(LSTM(64))
model.add(Dense(total_words, activation=’softmax’))
model.build(input_shape=(None, max_line_len – 1))
model.summary()
RNN
LSTM -க்கான அதே புரோகிராமில் கீழ்க்கண்ட இடத்தில் உள்ள வரியை மட்டும் மாற்றினால், அதுவே RNN மாடலுக்கானது!
model.add(Embedding(total_words, 100, input_length=max_line_len-1))
model.add(SimpleRNN(150))
model.add(LSTM(100))
இங்கு LSTM போல நான்கு gates இல்லாத காரணத்தால், பின்வரும் மதிப்பு நான்கால் பெருக்கப்படாமல் அப்படியே வெளிப்படுவதை அதன் summary-ல் காணலாம்.
150 * (100+150+1) = 37,650