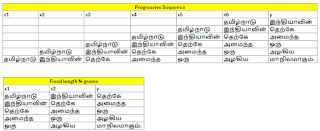
Sequential vs N-gram Training data
இதுவரை நாம் உருவாக்கியுள்ள பயிற்சி டேட்டா அனைத்தையும், முதல் வார்த்தையிலிருந்து துவங்கி கொஞ்சம் கொஞ்சமாக சொற்களை அதிகரிக்கும் வண்ணமே அமைத்துள்ளோம். எடுத்துக்காட்டாக,
- தமிழ்நாடு இந்தியாவின்
- தமிழ்நாடு இந்தியாவின் தெற்கே
- தமிழ்நாடு இந்தியாவின் தெற்கே அமைந்த
- தமிழ்நாடு இந்தியாவின் தெற்கே அமைந்த ஒரு
- தமிழ்நாடு இந்தியாவின் தெற்கே அமைந்த ஒரு அழகிய
என்று ஒவ்வொரு முறையும் முதல் வார்த்தையிலிருந்தே ஆரம்பிக்கின்றோம். இதன் காரணமாக திடீரென இடையிடையே உள்ள சொற்களைக் கொடுத்து “அடுத்து என்ன?” என்பதை பிரிடிக்ட் செய்யச் சொன்னால் மாடலால் முடியாது. ஏனெனில் பயிற்சி டேட்டா அது போன்று அமையவில்லை. திடீரென “தெற்கே” என்பதைக் கொடுத்து, அடுத்து என்ன வரும்? எனக் கேட்டால் மாடலால் முடியாது. அதுவே, “தமிழ்நாடு இந்தியாவின் தெற்கே” எனக் கொடுத்தால் பிரிடிக்ட் செய்துவிடும். ஆகவே பயிற்சி டேட்டாவை உருவாக்கும் போதே, ஒரு சொற்றொடரின் இடையிடையே உள்ள வார்த்தைகளும் ஆரம்ப வார்த்தைகளாக அமையுமாறு உருவாக்குவதற்கு N-gram Method உதவுகிறது. இது பின்வருமாறு.
- தமிழ்நாடு இந்தியாவின் தெற்கே
- இந்தியாவின் தெற்கே அமைந்த
- தெற்கே அமைந்த ஒரு
- அமைந்த ஒரு அழகிய
- ஒரு அழகிய மாநிலமாகும்
ஒரு பெரிய வாக்கியத்தை எந்த அளவுக்கு குட்டி குட்டியாக வெட்டி ட்ரெய்னிங் டேட்டாவை உருவாக்கலாம் எனக் குறிப்பிடுவது விண்டோ சைஸ் ஆகும். Window size = 2 என்பது bigrams எனவும், 3 என்பது trigrams எனவும் அழைக்கப்படும். இதுபோல எவ்வளவு வேண்டுமானாலும் அமைக்கலாம்.
N-grams முறையில் ட்ரெய்னிங் டேட்டாவை உருவாக்கி LSTM மாடலுக்கு பயிற்சி அளிப்பதற்கான நிரல் பின்வருமாறு.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| import numpy as np | |
| import tensorflow as tf | |
| from tensorflow.keras.preprocessing.text import Tokenizer | |
| from tensorflow.keras.models import Sequential | |
| from tensorflow.keras.layers import Embedding, LSTM, Dense | |
| from tensorflow.keras.preprocessing.sequence import pad_sequences | |
| x = "தமிழ்நாடு இந்தியாவின் தெற்கே அமைந்த ஒரு அழகிய மாநிலமாகும். இது பல்வேறு கலாச்சார பாரம்பரியங்களையும், செழிப்பான சாகுபடிமுறையையும் கொண்டுள்ளது. தமிழ்நாட்டின் தலைநகரமான சென்னை, தொழில்நுட்பம் மற்றும் கல்வியில் முன்னணி வகிக்கிறது. மாமல்லபுரம், தஞ்சாவூர் பெரிய கோயில் போன்ற வரலாற்று முக்கியத்துவம் வாய்ந்த இடங்கள் சுற்றுலாப் பயணிகளை ஈர்க்கின்றன. தமிழ்நாட்டின் கலை, இலக்கியம் மற்றும் இசை உலகளாவிய புகழ் பெற்றவை" | |
| tokens = Tokenizer() | |
| tokens.fit_on_texts([x]) | |
| dictionary = tokens.word_index | |
| x_n_grams = [] | |
| y_n_grams = [] | |
| window_size = 3 | |
| for line in x.split('.'): | |
| line_tokens = tokens.texts_to_sequences([line])[0] | |
| for i in range(len(line_tokens) – window_size): | |
| n_grams = line_tokens[i:i + window_size] | |
| label = line_tokens[i + window_size] | |
| x_n_grams.append(n_grams) | |
| y_n_grams.append(label) | |
| max_line_len = max([len(i) for i in x_n_grams]) | |
| total_words = len(dictionary) + 1 | |
| train_X = np.array(pad_sequences(x_n_grams, maxlen=max_line_len, padding='pre')) | |
| y = np.array(tf.keras.utils.to_categorical(y_n_grams, num_classes=total_words)) | |
| model = Sequential() | |
| model.add(Embedding(total_words, 100, input_length=max_line_len-1)) | |
| model.add(LSTM(150)) | |
| model.add(Dense(total_words, activation='softmax')) | |
| model.build(input_shape=(None, max_line_len-1)) | |
| print(model.summary()) | |
| model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) | |
| model.fit(train_X, y, epochs=100, verbose=1) | |
| input_text = "தமிழ்நாடு இந்தியாவின் தெற்கே" | |
| input_token = tokens.texts_to_sequences([input_text])[0] | |
| input_x = pad_sequences([input_token], maxlen=max_line_len-1, padding='pre') | |
| predicted = np.argmax(model.predict(input_x), axis=-1) | |
| for word, index in tokens.word_index.items(): | |
| if index == predicted: | |
| print (word) |